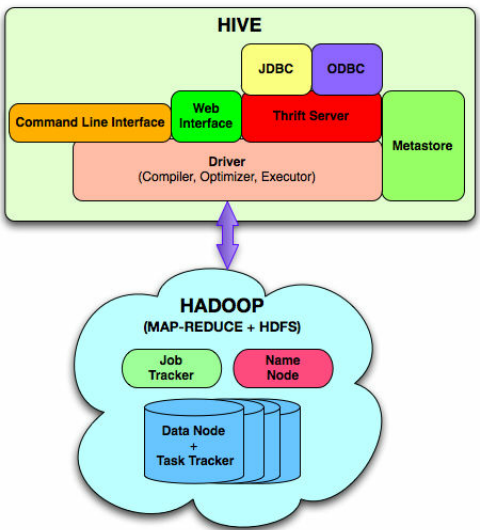
What is Hive?
The Apache Hive ™ data warehouse software facilitates reading, writing, and managing large datasets residing in distributed storage using SQL. Structure can be projected onto data already in storage. A command line tool and JDBC driver are provided to connect users to Hive.
Hive provides the following features:
- Tools to enable easy access to data via SQL, thus enabling data warehousing tasks such as extract/transform/load (ETL), reporting, and data analysis.
- A mechanism to impose structure on a variety of data formats
- Access to files stored either directly in Apache HDFS™ or in other data storage systems such as Apache HBase™
- Query execution via Apache Tez™, Apache Spark™, or MapReduce
- Procedural language with HPL-SQL
- Sub-second query retrieval via Hive LLAP, Apache YARN and Apache Slider.
Components of Hive include HCatalog and WebHCat.
HCatalog is a table and storage management layer for Hadoop that enables users with different data processing tools — including Pig and MapReduce — to more easily read and write data on the grid.
WebHCat provides a service that you can use to run Hadoop MapReduce (or YARN), Pig, Hive jobs. You can also perform Hive metadata operations using an HTTP (REST style) interface.
Shasta Tek in Hive
Shasta Tek has several years of expertise in MS SQL platform. It has been an easy transformation to translate them into Hive queries (HQL), both using command line interface(hive shell) as well as complex queries. These queries are broken down by the hive service into map-reduce jobs to execute across the Hadoop cluster. We can create JDBC/ ODBC applications that use the JDBC/ ODBC drivers to access the data in Hive.
We can create reports using summary data to produce columnar reports, pie chart, bar diagram and so on. We are pushing the one-day incremental data to the delta table and check the data exists in the target table or not. If exists update the end date and insert all the records in the delta table to the target table. we are maintaining the historical records. Meta Store is a repository of metadata and the driver receives the HiveQL statements and works like a controller. We created a view to avoiding the complex queries. It helps to improve the developer productivity which comes at the cost of increasing latency, and decreasing efficiency. We can evaluate and advise the client on the intelligent use of Hive where appropriate.