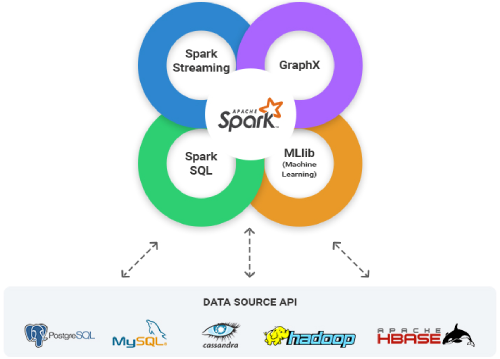
Apache Spark Ecosystem
Being part of the Big data platform, Apache Spark provides an interface for programming entire clusters with implicit data parallelism and fault-tolerance.
Apache spark is a unified framework that can handle data in both batch mode and real-time streaming. It has been built on top of Scala and runs on a JVM.
It has library components such as Spark SQL to handle structured data, spark streaming for near real-time data processing and MIib for machine learning with industry-wide accepted algorithms built-in and Graphx for graph processing and computation related to graphs.
Spark is a distributed computational engine, addressing the resilience and compute requirements. It has a driver program in the spark shell that creates a spark context from the developer submitted programs and the cluster manager manages communication and coordination with the resources like the worker nodes to execute the tasks in each of the nodes.
Spark SQL is a Spark module for structured data processing. It provides a programming abstraction called DataFrames and can also act as distributed SQL query engine. It enables unmodified Hadoop Hive queries to run up to 100x faster on existing deployments and data. It also provides powerful integration with the rest of the Spark ecosystem.
Many applications need the ability to process and analyze not only batch data but also streams of new data in real-time. Running on top of Spark, Spark Streaming enables powerful interactive and analytical applications across both streaming and historical data while inheriting Spark’s ease of use and fault tolerance characteristics.
Machine learning has quickly emerged as a critical piece in mining Big Data for actionable insights. Built on top of Spark, MLlib is a scalable machine learning library that delivers both high-quality algorithms and blazing speed. The library is usable in Java, Scala, and Python as part of Spark applications, so that you can include it incomplete workflows.
GraphX is a graph computation engine built on top of Spark that enables users to interactively build, transform and reason about graph-structured data at scale. It comes complete with a library of common algorithms.
Shasta Tek on Apache Spark
We have migrated the complete Data integration, reporting and analytics developed in MS SQL Server to Hadoop and Apache framework for a leading Telecom service provider.
Our main concern is to maintain speed in processing large datasets in terms of waiting time between queries and waiting time to run the program.
It handles in two ways - One is storage and second is processing. We are processing the streaming ETL data on a daily basis.
In Traditional ETL (extract, transform, load) tools used for batch processing in data warehouse environments must read data, convert it to a database compatible format, and then write it to the target database. With Streaming ETL, data is continually cleaned and aggregated before it is pushed into data stores. Code written for ETL is on Scala programming language. Every time program run up to 100 times faster in memory and 10 times faster in a disk. We are using Spark SQL for querying the data via HIVE Query Language and manipulating graphs using GraphX library.