What is Cassandra?
The Apache Cassandra database is the right choice when you need scalability and high availability without compromising performance. Linear scalability and proven fault-tolerance on commodity hardware or cloud infrastructure make it the perfect platform for mission-critical data. Cassandra's support for replicating across multiple datacenters is best-in-class, providing lower latency for your users and the peace of mind of knowing that you can survive regional outages.
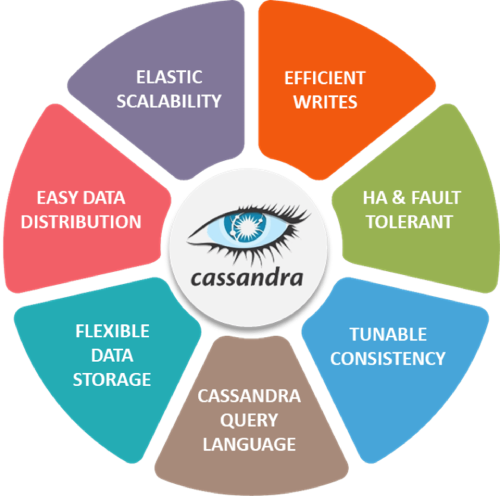
Given below are some of the features of Cassandra:
- Elastic Scalability - Cassandra is highly scalable; it allows to add more hardware to accommodate more customers and more data as per requirement.
- Always on Architecture - Cassandra has no single point of failure and it is continuously available for business-critical applications that cannot afford a failure.
- Fast Linear-scale Performance - Cassandra is linearly scalable, i.e., it increases your throughput as you increase the number of nodes in the cluster. Therefore it maintains a quick response time.
- Flexible Data Storage - Cassandra accommodates all possible data formats including: structured, semi-structured, and unstructured. It can dynamically accommodate changes to your data structures according to your need.
- Easy Data Distribution - Cassandra provides the flexibility to distribute data where you need by replicating data across multiple data centers.
- Transaction Support - Cassandra supports properties like Atomicity, Consistency, Isolation, and Durability (ACID).
- Fast Writes - Cassandra was designed to run on cheap commodity hardware. It performs blazingly fast writes and can store hundreds of terabytes of data, without sacrificing the read efficiency.
Apache Cassandra
Shasta Tek made Cassandra as the storage medium for sentiment analysis requirement. Sentiment analysis is the process of computationally identifying and categorizing the opinions expressed in a piece of text, especially in order to determine whether the user’s attitude towards a particular topic, product, movie, polling and etc., These are categorized in Positive, More Positive, Negative, More Negative, Not Understood and Natural. We will ignore the context in which the opinions are expressed.
Technologies used: Twitter as a source data platform, Spark/Scala for loading data into Cassandra data storage, Stanford NLP algorithm for text mining and Power BI and SAS Iaap for charts, reporting and dashboards.
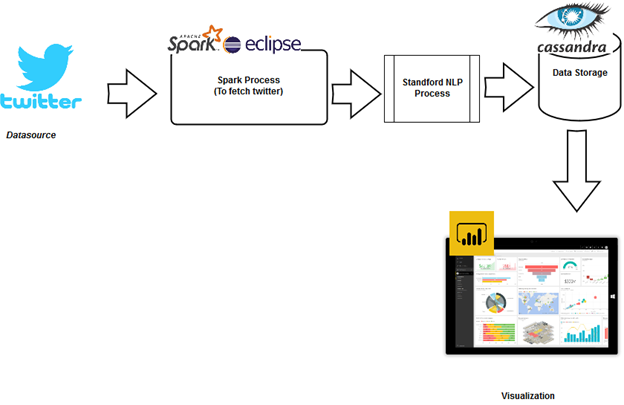
Application Architecture
The Twitter streaming data is fetched using Twitter credentials, spark processes the data and load the same into Cassandra DB for analytical purpose.
Data visualization is enabled using Power BI, which connects to Cassandra DB through ODBC. We also have an option to create a real-time dashboard using our
Own tool STS iAAP. We have an auto-refresh option to update the charts at specified intervals.
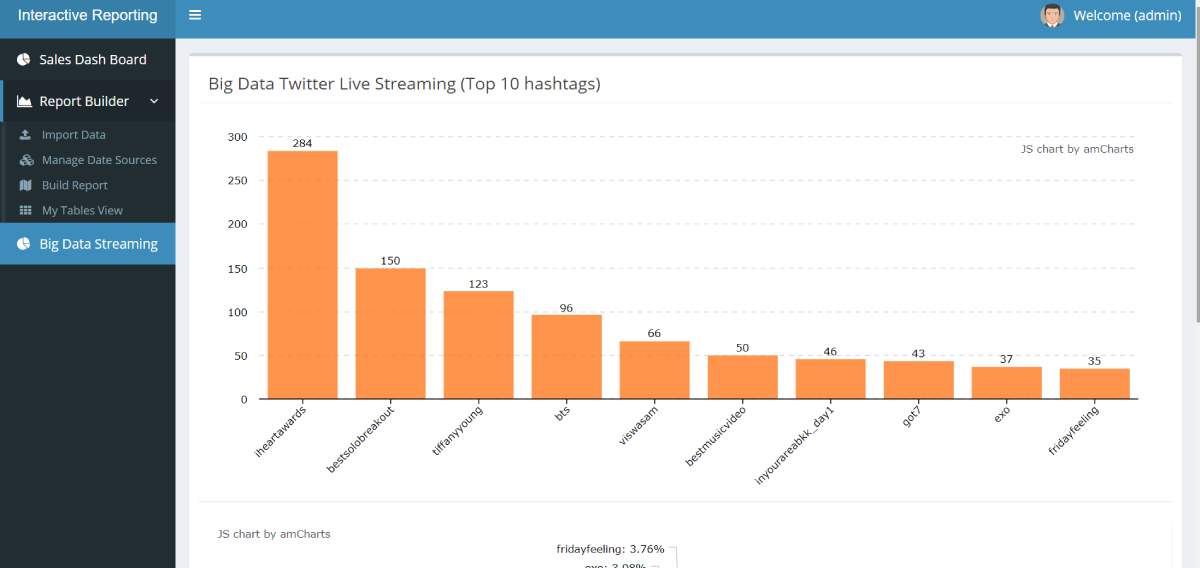
Typically the chart would look as below providing overall stats for all Hashtags from Twitter.
Dashboard through STS iAPP